1. Distributed System
Before deep diving into concepts, let’s define what a distributed sdisstem is. The best definition is from Tim Berglund in an O’Reilly lesson: “distributed systems […] are a collection of independent computers that appears to its user as a single computer”.
Distributed systems are a collection of independent computers that appears to its user as a single computer.
2. Availability
A system is available when service interruption is minimal which means downtime and failures are punctual.
To quantify service availability, indicator setup is a prerequisite. In Service Reliability Engineering (SRE) terms, it is named Service-Level Indicator (SLI). Common examples of SLI are: latency, responsiveness, error rates. Based on these indicators, it is possible to define a numbered internal target, the Service-Level Objective (SLO). Then, the Service-Level Agreement (SLA), which can be defined as the uptime system percentage on a time window promised to a customer, will be compared to the SLO.
SLA: agreed with the client
SLO: internal target
SLI: real measure of the service availability
3. Horizontal scalability
Scaling is involved when the limit (number of requests, CPU, RAM, …) a resource can handle is reached. Components are duplicated and available in the pool of resources. Scalability is used at different layers: network, service, database.
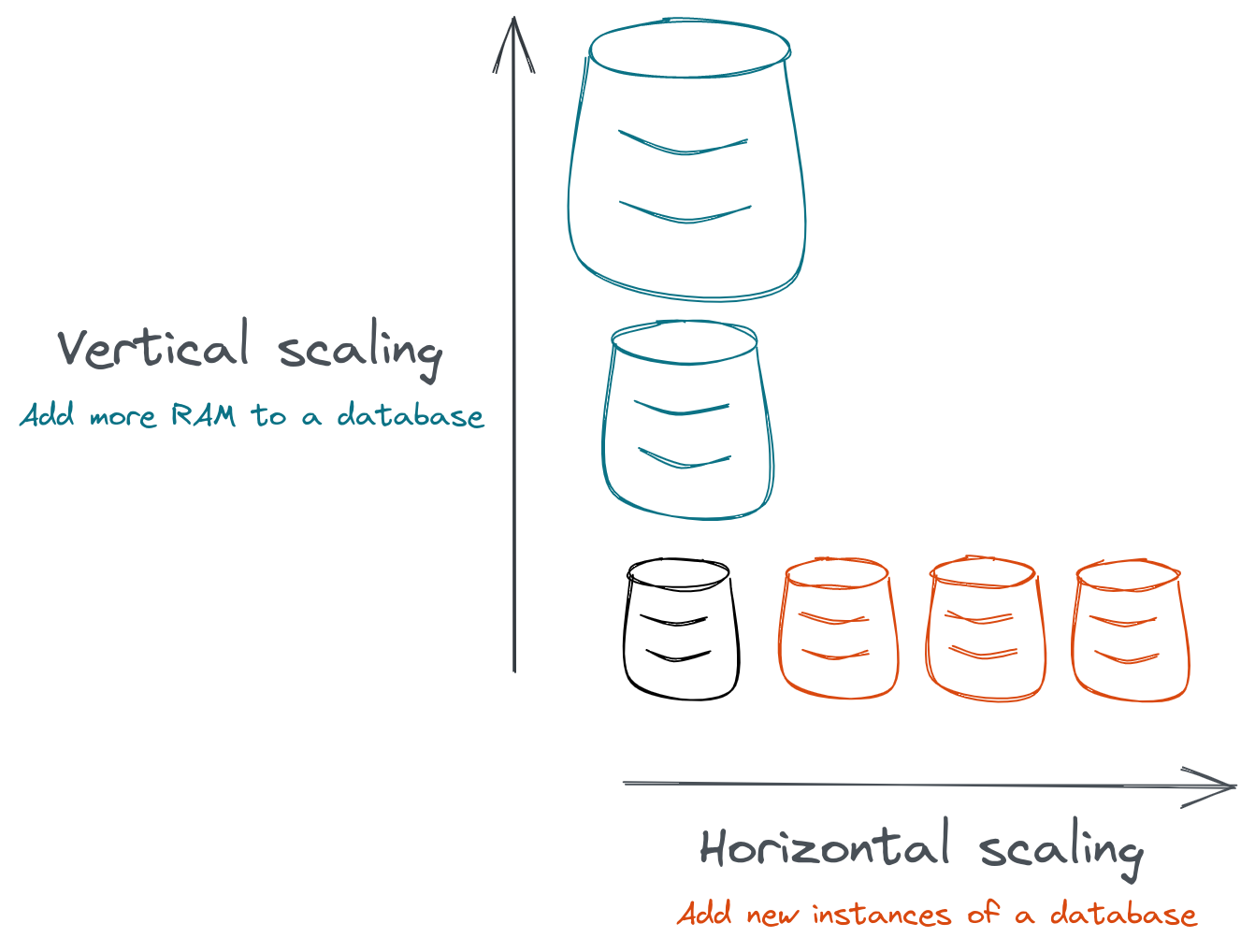 Vertical and horizontal database scaling schema by doniacld
Vertical and horizontal database scaling schema by doniacld
4. Low latency
Latency is the amount of time the system takes to process a request, measured most often in milliseconds. To reach the low latency, possible solutions are caching or Content Delivery Network (CDN).
5. Load balancing
A load balancer distributes requests between services, by appearing as a single entrypoint to the caller. It provides easy scalability and availability features. Note that a multitude of algorithms exist behind the decision-making. One of the most used is Round Robin.
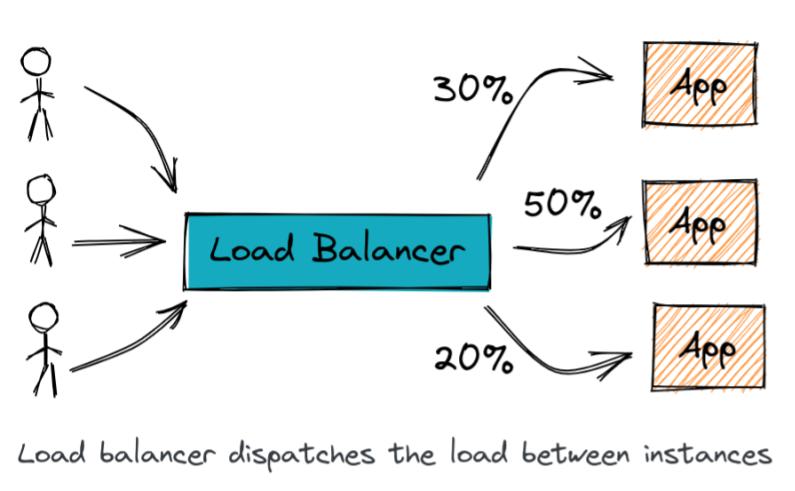 Load balancer example by doniacld
Load balancer example by doniacld
6. Caching
Caching is copying data in temporary storage to accelerate memory access. Web browsers and CDN servers cache content that is seldom updated. By reducing the latency and the load on the backend server, we increase the customer success.
Temporary storage means evicting outdated content by using a strategy such as First In First out (FIFO), Least Recently Used (LRU) or Least Frequently Used (LFU) to mention just a few. Redis and Memcache are frequently used as hot/cache databases.
7. Replication
Replication consists in sharing data while maintaining consistency between redundant resources. It is used when high availability and accessibility are required. The continuous replication can be synchronous or asynchronous. It depends on the necessary level of consistency associated with the system design architecture.
8. Sharding
Sharding refers to distributing the data storage among several instances of a database in order to make horizontal scaling and replication possible. Here are different types of sharding strategies:
- key based sharding
- range based sharding
- directory based sharding
Some applications natively handle sharding such as Cassandra or MongoDB whereas Redis and Memcache are non-natively sharded.
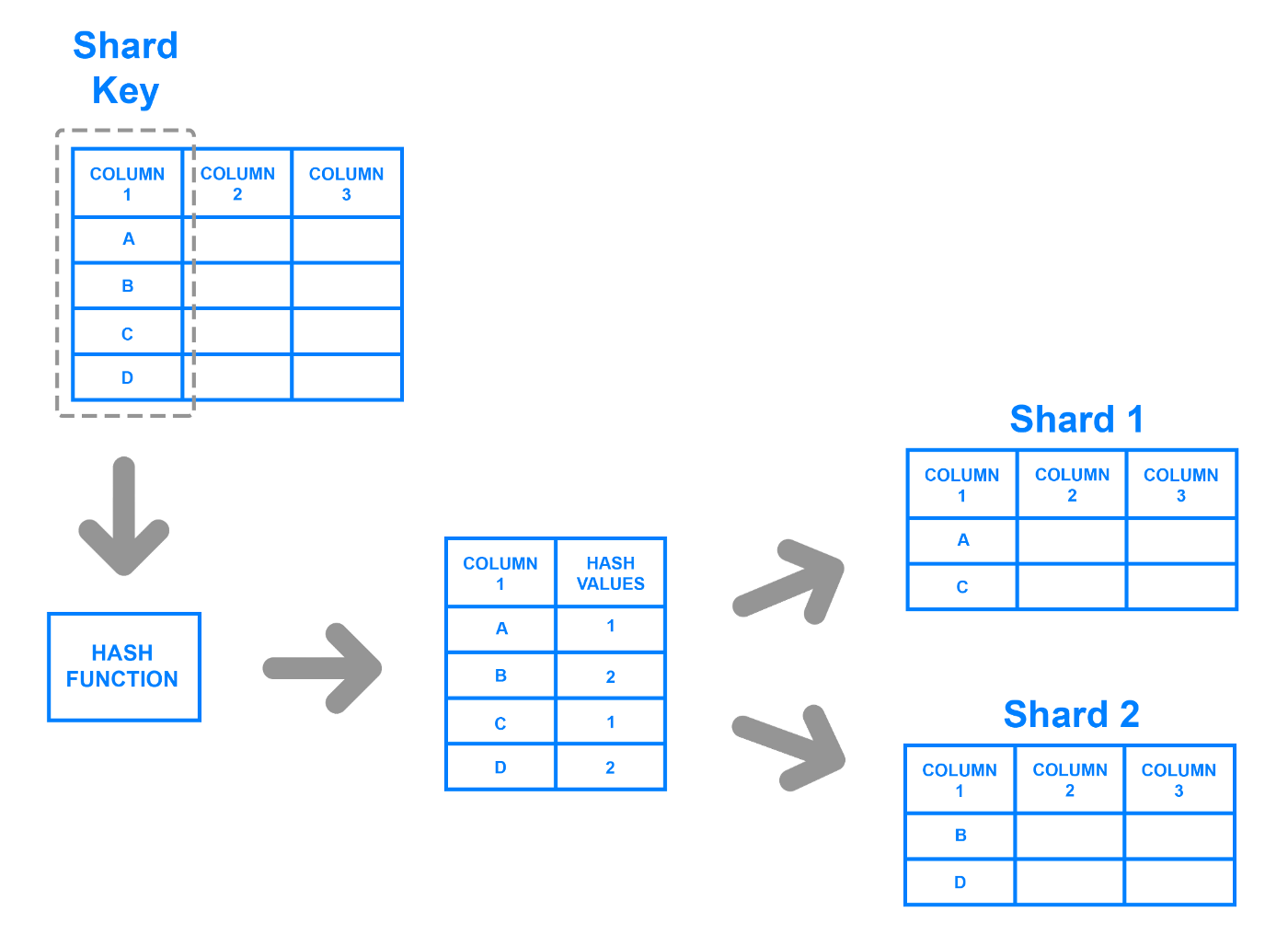 Key based sharding example from DigitalOcean
Key based sharding example from DigitalOcean
9. Monitoring
Monitoring consists in collecting, processing, aggregating, and displaying real-time quantitative data about a system, such as query counts and types, error counts and types, processing times, and server lifetimes. * There are two types of monitoring: black box and white box. In black box monitoring, you get the same level of information as an end user. In white box monitoring, the system knows infrastructure and code details.
The four golden signals are: latency, traffic, errors, saturation.
Monitoring is not only useful to proactively detect abnormal system behaviour but also to retrieve information in order to analyse customer needs.
10. Observability
A system is observable when there are sensors translating its behaviours and activities, so that it can be evaluated based on this output. The system should generate data in three formats to make the observability exploitable: event logs, metrics, and traces.
To go further
Distributed systems: A quick and simple definition
Reliability vs availability in fault tolerance
System design for interviews
Load balancing for system design interview
What is caching ?
How sharding works ?
MongoDB: database sharding explained
SRE book: monitoring for distributed systems
Glossary SummoLogic: Observability
I Am On Demand: Distributed monitoring 101
*Site Reliability Engineering by Rob Ewaschuk published by O’Reilly